
GxP Lifeline
Think Inside the JSON: A Reinforcement Strategy for Strict LLM Schema Adherence

MasterControl AI Research
Background
Getting production processes off paper and digitized continues to be a company goal for life sciences manufacturers. For many, even after the purchase of a manufacturing execution system (MES) like MasterControl Manufacturing Excellence, the process to examine and rethink their current manual or paper processes and then go about building digital production records is time-consuming, as is revising those records. All of this opens manufacturers up to human error and could ultimately lead to compliance issues.
Being able to better automate that process of initial digital batch builds and reduce revisions needed in records due to good documentation practice (GDP) or compliance errors can help streamline the process and more quickly show the return on investment (ROI) on digitizing. MasterControl recognizes that the concept of “right first time” expands beyond production—to quickly and effectively transition to an electronic batch record right the first time to reduce or eliminate errors. This blog post outlines the approach MasterControl is taking to develop our own proprietary methodology to introduce artificial intelligence (AI) into Master Template builds to help customers both optimize and standardize batch records more efficiently and improve decision-making in their digital transformation journey.
Introduction
In biomanufacturing templates, ensuring that AI-generated data stays strictly compliant with a predefined schema is crucial for quality assurance and regulatory compliance. Despite the immense language generation abilities of modern large language models (LLMs), they often produce text that violates structured output requirements—introducing errors like missing fields or malformed JavaScript Object Notation (JSON). Such deviations disrupt automated pipelines, create compliance headaches, and increase manual corrections.
MasterControl therefore introduces ThinkJSON, a reinforcement-learning-driven approach using DeepSeek R1 methodology that teaches a 1.5B-parameter model to produce strict, schema-constrained outputs. By fusing a novel synthetic dataset (for reasoning) with custom reward functions under Group Relative Policy Optimization (GRPO), we maintain precise control over how the model structures its responses. Here’s how it all works.
Background: Why Schema Adherence Matters
In life science manufacturing—an industry historically dominated by paper records—digital transformations must adhere to strict schema rules for every log entry or batch record. Any stray delimiter or inconsistent key can:
- Break machine-driven pipelines.
- Vitiate the integrity of the digital record.
- Trigger compliance violations leading to costly audits or rework.
Although LLMs excel at free-form text, they lack an intrinsic mechanism to keep outputs in perfect format. Various solutions exist, including:
- Supervised Fine-Tuning (SFT): Use large, curated datasets to make the model produce correct formats. But it’s expensive and risks overfitting.
- Reinforcement Learning With Human Feedback (RLHF): Align the model using reward signals. But it demands extensive high-quality feedback.
- Constraint-Based Decoding: Intercept tokens that violate a schema. Guaranteed but can add runtime complexity.
- Prompt Engineering: Provide explicit instructions or layout hints. Easier to adopt but doesn’t guarantee consistent compliance.
Our Approach: ThinkJSON With Reinforcement + Fine-Tuning Leverages DeepSeek R1 Key Ideas
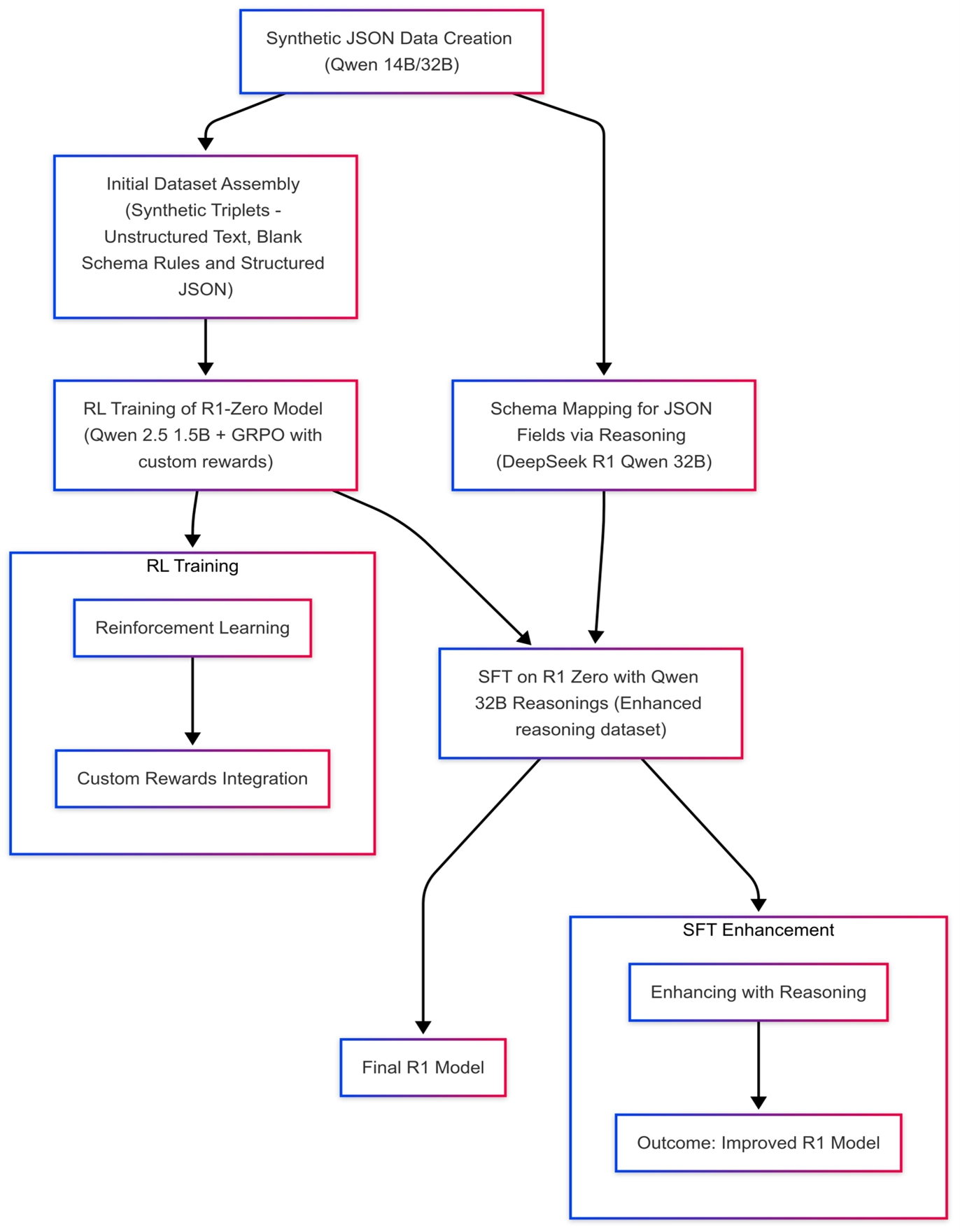
1. Synthetic Reasoning Dataset Construction
- We generate triplet data: filled JSON schemas (with nested components, tables, etc.), unstructured text describing the same content in multiple styles (ASCII tables, PDF-like snippets, etc.) and reasoning on mapping of unstructured data to structured.
- We produce blank schemas as well, so the model can learn how to “reverse-engineer” the text into a valid structure.
2. Reinforcement Learning
- We train a 1.5B-parameter base model using Group Relative Policy Optimization (GRPO)—custom rewards check JSON validity, structural faithfulness, and tag correctness.
- By ranking model completions in a sampled group and rewarding the top performers, the LLM learns to consistently produce schema-compliant outputs.
3. Supervised Fine-Tuning
- Finally, we refine the model using SFT, aligning it to downstream domain specifics. Reinforcement Learning (RL) alone confers reasoning power; SFT ensures the final touches, so every field is correctly spelled and placed.
Training Setup
- Reinforcement Dataset: 20K unstructured to structured samples specialized for hierarchical, schema-based tasks.
- Supervised Set: 10K “reasoning” samples, each pairing text-to-JSON to reasoning steps.
- Compute: ~20 hours on an 8×H100 GPU cluster and three hours on 1xA100. Efficient enough for mid-sized teams.
During the RL phase, each model output is scored by multiple custom rewards:
- JSON-Based Reward: Rates key-value match, ensures no extraneous fields, checks JSON length similarity.
- Format Verification: Ensures mandatory tags (<think> / <answer>) appear correctly.
- GRPO Aggregation: Combines partial rewards into a final advantage score, guiding policy updates.
After establishing solid schema reasoning through RL, SFT cements domain-specific norms. This hybrid training pipeline—reinforcement + supervised—achieves a “best-of-both-worlds” synergy.
Results
We benchmarked ThinkJSON against:
- Original DeepSeek R1 (671 B).
- Distilled DeepSeek R1 (Qwen-1.5B / Qwen-7B).
- Gemini 2.0 Flash (70B).
Key Metrics:
- No Extracted JSON: The model produced no structured output.
- Valid JSON: The output is syntactically correct JSON.
- Mean Match %: Proportion of fields correctly mapped.
- Mean Noise %: Extraneous/unwanted tokens.
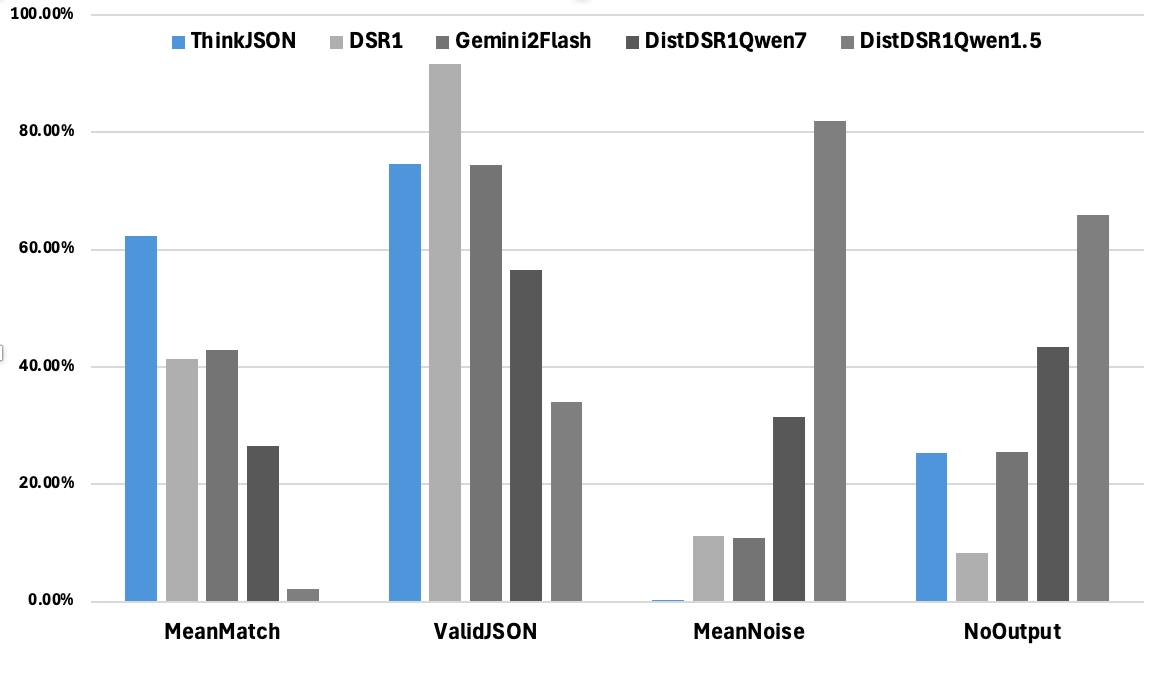
ThinkJSON stands out with a 62.41% mean match (highest) and just 0.27% noise (lowest). It surpasses alternative solutions that either yield incomplete JSON or degrade with noise. For instance, Original DeepSeek R1 hits 41.43% match / 11.14% noise, while Gemini 2.0 Flash manages 42.88% match but at 10.86% noise. Distilled models Qwen-1.5B/7B handle fewer rows validly and produce higher extraneous content.
Discussion and Future Directions
- Universality Beyond Math: Original DeepSeek R1 focused on math/science reasoning. ThinkJSON showcases versatile reasoning that handles hierarchical text, domain constraints, and compliance-driven requirements.
- Low Compute Footprint: Despite a mere 20-hour training window on an 8×H100 cluster and 3-hours on 1xA100, the model’s performance remains robust, demonstrating that strict schema fidelity can be achieved without a massive hardware budget.
- Scalability to Larger Base Models: Our current 1.5B-parameter foundation model could be scaled to 7B parameters for broader contextual understanding—especially beneficial in complex QA processes in life science manufacturing. Future studies will assess how bigger backbones further improve schema adherence under the same Group Relative Policy Optimization (GRPO) framework.
Overall, ThinkJSON offers a budget-friendly, compliance-ready approach for generating structured text in real-world, regulated domains like life science manufacturing—balancing the general reasoning potential of RL with the tight constraints demanded by industry.
References
- DeepSeek R1, DeepSeek-AI, 2025.
- Brandon T. Willard et al., “Efficient Guided Generation for Large Language Models,” 2023.
- Connor Shorten et al., “StructuredRAG: JSON Response Formatting with Large Language Models,” 2024.
- Michael Liu et al., “We Need Structured Output,” 2024.
- Yixin Dong et al., “Xgrammar: Flexible and Efficient Structured Generation,” 2024.
For more details, check out the datasets and models:
https://huggingface.co/datasets/MasterControlAIML/R1-Reasoning-Unstructured-To-Structured
https://huggingface.co/datasets/MasterControlAIML/JSON-Unstructured-Structured

Dr. Rojkova has been building and operating revenue-generating machine learning services and helping companies integrate AI for more than 15 years.
Prior to MasterControl, she led the team of ML and ML Ops engineers at Deloitte to build and support multimodal applications, such as computer vision and predictive maintenance for power and utilities, medical image segmentation, spoken task-oriented language-agnostic dialogue assistants, knowledge graphs, and policy learning for healthcare and life sciences. She also carries ML and NLP experience from Apple, LifeLock/IDAnalytics, and Kernel.
Dr. Rojkova completed her undergraduate degree in neuroscience at Moscow State University before completing a master's degree in psychology and cognitive neuroscience at the University of Illinois- Urbana Champaign and PhD in Computer Science at the University of Louisville. She has authored and co-authored papers and patents in the field of applied AI and ML.
Free Resource

Enjoying this blog? Learn More.
How to Implement AI in Life Sciences Quality: 5 Strategic Areas
Download Now